从VGG到I3D:注视序列相似度的双路径探索
数据集
本项目选用了开源眼动数据集 CAT2000 作为研究对象。虽然从科研创新的角度来看,使用实验室“自制”数据集更能体现团队在数据采集上的实力与原创性,但在没有条件收集原始数据的情况下,采用开源数据集不仅具有可重复性,也便于与已有研究成果进行对比。开源数据集在计算机视觉领域已成为基础科研设施,其价值不可忽视。
CAT2000 数据集中包含了不同主题类别下的图像,以及志愿者观看这些图像时的眼动数据。图像按照类别以 JPG 格式保存在不同文件夹中,而所有眼动数据则集中存储在一个复杂的 .mat 文件中。这类 .mat 文件包含 MATLAB 独有的数据结构,难以被 Python 常用库如 scipy.io 正确解析。
为了解决这一问题,我使用 MATLAB 将每张图片对应的个体眼动数据提取并转换为 .csv 格式,分别保存在与图片同名的文件夹下。每张图片大约对应18个被试者的数据。
数据目录结构
为了便于后续处理与分析,我们将 CAT2000 数据集的图像与转换后的眼动数据按统一结构组织。每类图像存放在以类别命名的文件夹中,每张图像对应一个同名文件夹,包含该图像下所有被试者的眼动轨迹数据,文件格式为 .eye(实际为 CSV 格式,扩展名用于区分)。
目录结构如下所示:
fixations
├─Action
│ ├─001.jpg
│ │ ├─10-11-jh.eye
│ │ ├─11-14-np.eye
│ │ ├─12-52-ng.eye
│ │ ├─...
│ ├─003.jpg
│ │ ├─10-11-jh.eye
│ │ ├─11-14-np.eye
│ │ ├─12-52-ng.eye
│ │ ├─...
├─Affective其中:
- 每个
.jpg文件为一张实验图片; - 每个
.eye文件夹记内包含一个名叫fixation.csv的csv文件记录被试在该图像上的眼动轨迹数据; .eye文件夹编码格式为{该分组编号}-{批次编号}-{缩写名}.eye,便于识别与分组分析。
很好,你提供的 CSV 文件格式如下:
X,Y
1014.8,778.6
813.6,609
884.1,487.8
...可见每个 .eye 文件只包含两列,分别表示注视点的横纵坐标,单位为像素。没有时间戳和持续时间,这说明你处理的是按顺序记录的注视点轨迹,用于还原扫描路径,而非注视点的精确时长或动态。
下面是报告中可以使用的 数据格式说明 部分内容:
眼动数据格式(fixation.csv 文件)
每个 fixation.csv 文件记录一名被试在特定图像上的注视轨迹,其为 CSV 格式,仅包含注视点的平面坐标信息,格式如下(以fixations\Action\001.jpg\2-54-hn.eye\fixation.csv为例):
X,Y
1.014800e+03,7.786000e+02
8.136000e+02,609
8.841000e+02,4.878000e+02
9.226000e+02,5.273000e+02
7.496000e+02,4.779000e+02
9.159000e+02,3.709000e+02
1.412200e+03,5.153000e+02
7.864000e+02,4.318000e+02
7.239000e+02,4.776000e+02
7.359000e+02,5.172000e+02
1.066400e+03,1.461400e+03
7.387000e+02,5.238000e+02
7.096000e+02,4.441000e+02
7.617000e+02,4.208000e+02
7.824000e+02,4.319000e+02
7.034000e+02,304
8.556000e+02,4.568000e+02字段说明:
X:注视点在图像上的横坐标,单位为像素;Y:注视点在图像上的纵坐标,单位为像素;- 每一行表示一个连续的注视点,按顺序记录观察轨迹;
- 所有注视点构成该被试对该图像的扫描路径(Scanpath);
数据中不包含时间戳和注视持续时间,仅保留注视顺序与空间位置,因此主要适用于路径重建与空间轨迹相似性分析等任务。更多关于注视采集方法与数据结构的详细信息,可参见 CAT2000 数据集的原始论文与说明文档@borji_cat2000_2015
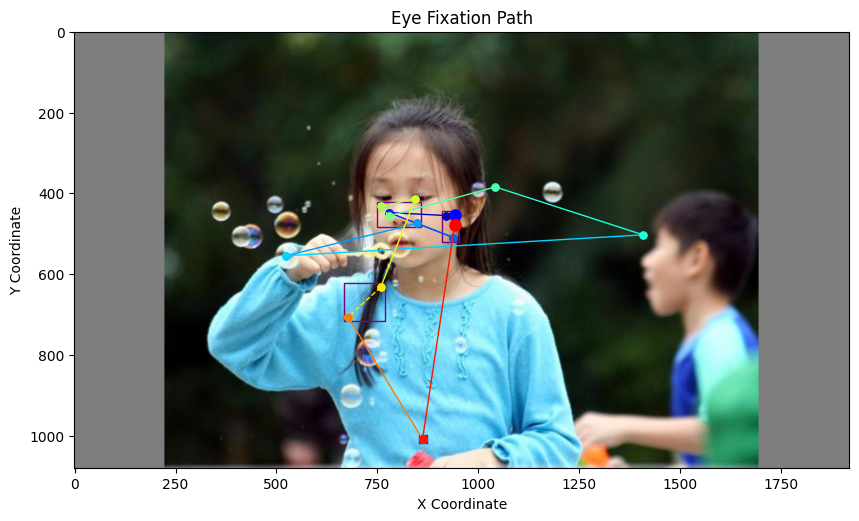
下图展示了一位被试者(2-54-hn)观看图像 001.jpg(类别:Action)时的注视序列
方法一:VGG16提取注视点特征
特征提取方式
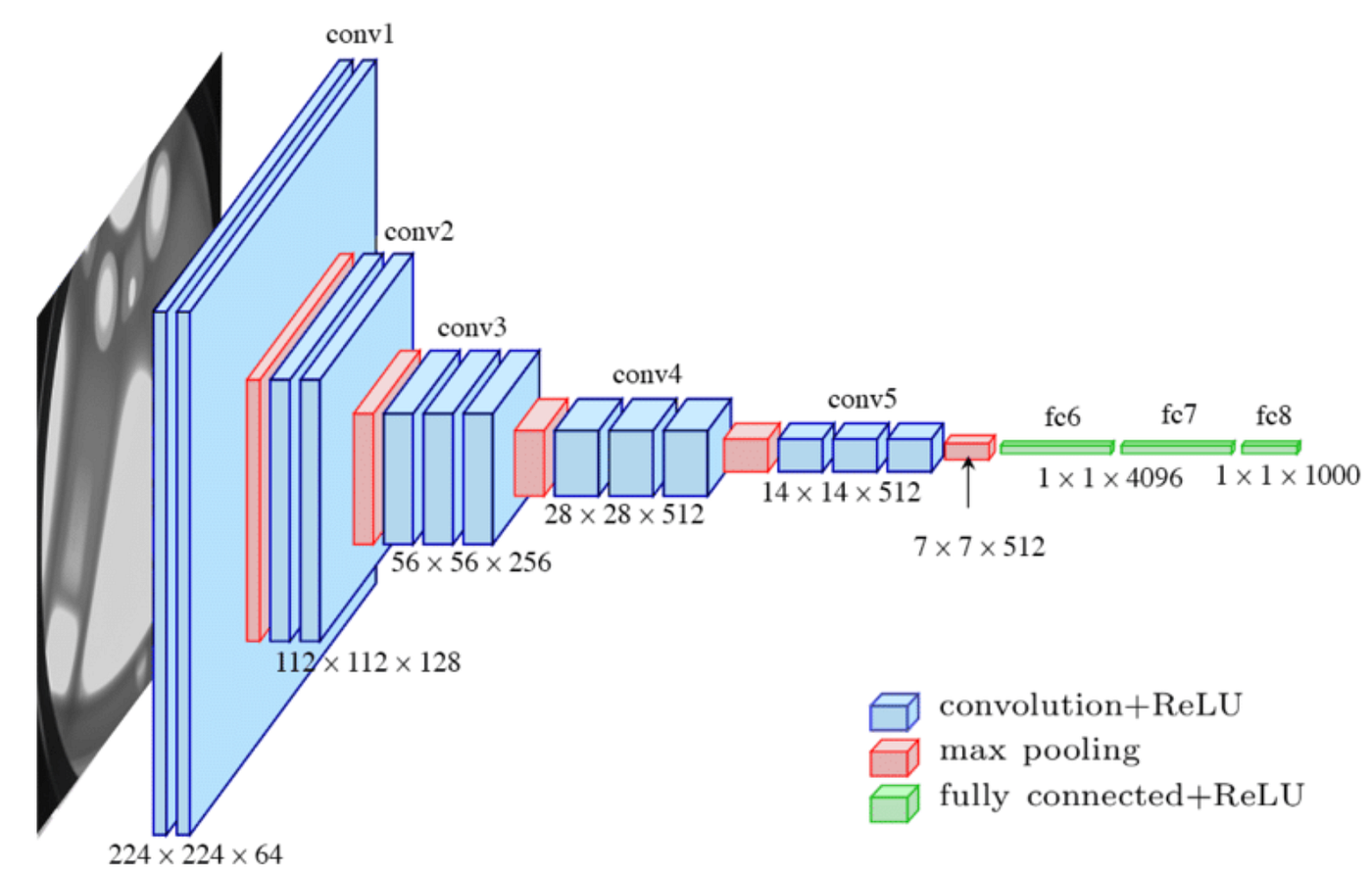
我们采用VGG16来进行特征提取,VGG16是一个深度卷积神经网络,由牛津大学的视觉几何组(Visual Geometry Group)开发。它在 ImageNet 数据集上表现出色,并且在许多计算机视觉任务中被广泛使用。大致可以理解成先卷积再通过全连接层分类,所谓特征就在卷积之后,全连接层是通过特征进行分类的,把物体的特征对应成分类的名词。所以我们使用 model.features 中的所有层,也就是 VGG16 的卷积和池化层部分(feature extractor部分),但没有用后面的全连接层(classifier部分)。
可以参见代码 src\utils.py :
model = models.vgg16(weights=models.VGG16_Weights.IMAGENET1K_V1)
model = nn.Sequential(*list(model.features.children())[:])
model.to(device)
model.eval()具体来说,model.features 包含了:
- 13个卷积层(Conv2d)
- 5个最大池化层(MaxPool2d)
- 激活函数(ReLU)
正如我在之前文章中说过的特征就是“机器世界”对于物体的描述,表现为一连串的浮点数,这串浮点数标记这该物体像什么,就像人类明确看见了一个物体但想不到对应的名词去描述一样。后续全连接层则是通过监督学习完成“像什么”到“是什么”的对应,在这里,你即使不知道一个东西怎么说,你仍然可以通过它“像什么”的描述知道两个事物是否相似,我们就由描述相似性推测现实相似性。既然描述是一串数字那么我们就可以用判断一串数字的相似性的方法去判断,可以用余弦相似度或者相关性系数,也有用绝对值相差之和的。
提取区域的大小
VGG16 网络设计用于处理 224×224 像素的输入图像,但我们都知道图片是可以放大缩小的,所以只要经过调整,VGG16 可以处理任意大小的输入图像。但是我们应该选取多大区域的图块来进行特征提取呢。我认为人能够关注的范围应该有生物学基础,就比如下图
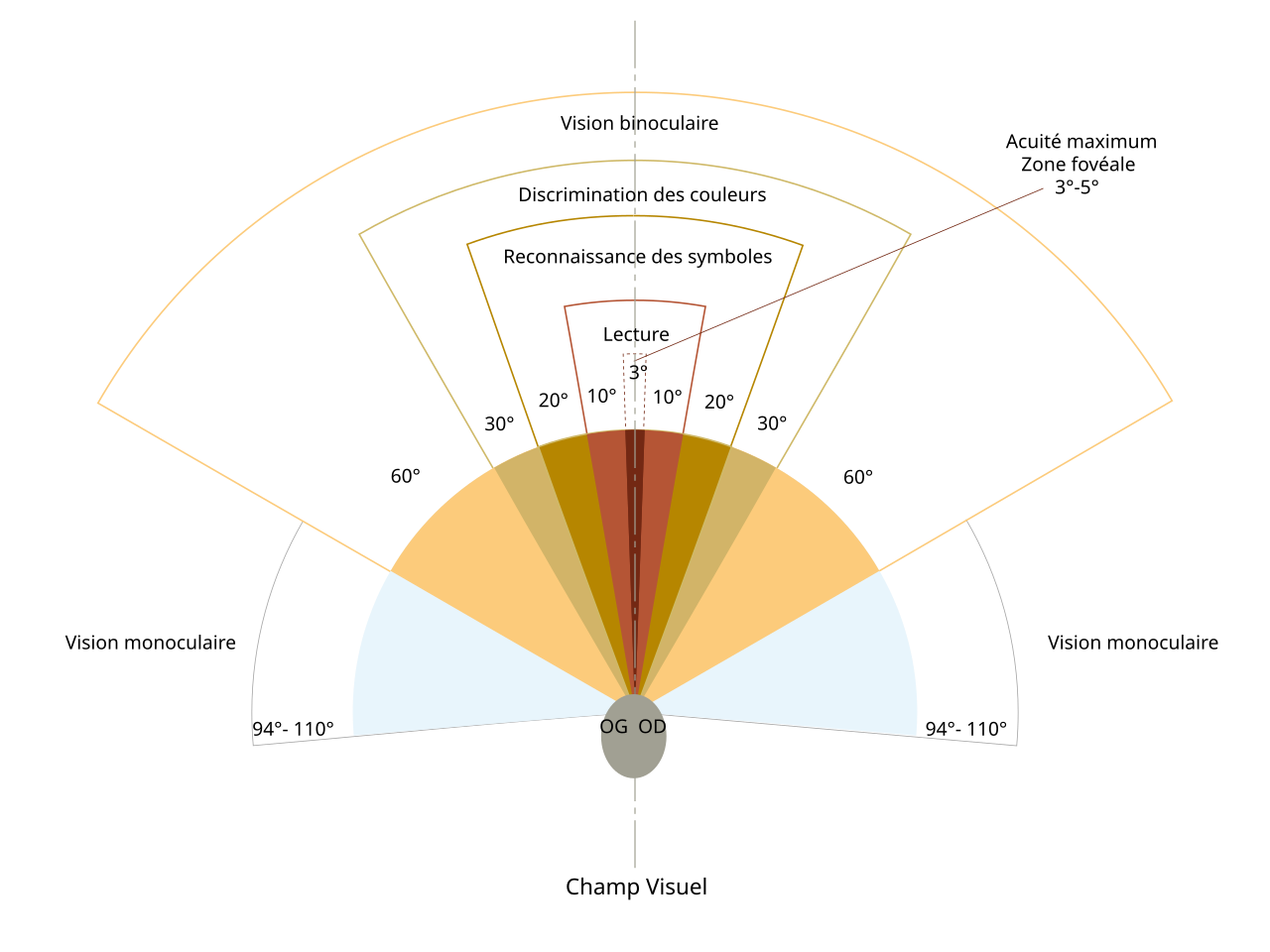
实际上人眼不同于照相机,相机是在CMOS上成像,CMOS是感光元件。但是人眼的感光细胞并不像CMOS那样均匀分布,感光细胞在“中央凹”最密集,这也是我们所谓“清楚观测”的范围就是3到5度,只不过眼球是可以转动的,当我们要看下一个区域的时候我们就把“中央凹”转过去,通过这小范围的清晰图像,我们脑补出全视野的清晰图像。不如就把人脑的辨认范围用作图片的特征提取范围。那我们要进行一些计算, 我们知道每度是38像素,那么3度到5度就是,114像素到190像素,由于中国人喜欢折衷,我就选择4度152像素。
degree of visual angle or dva about 38 pixels(see Borji and Itti 2015)
提取区域的形状
由于人眼的中央凹大致是圆形或椭圆形,而不是方形,所有我用等面积的圆形替换掉152x152像素的方形来进行测试看是否能够提升效果。用圆形的提取区域是最自然的,但是VGG16网络特征提取只支持正方形,所有要经过填充,计算机术语叫“掩码”。然后才能够进行特征提取。具体效果,我需要对比才可以知道,但是这是合理的。不过考虑到正方形和等面积的圆实际上相差不大,所有也不会有突飞猛进的效果。
扫视路径相似性计算(Scanpath Similarity)
本项目参考了Nora Castner等人提出的《Deep Semantic Gaze Embedding and Scanpath Comparison for Expertise Classification during OPT Viewing》Castner et al. (2020) 一文中的方法.
我们使用 Smith-Waterman 局部序列比对算法 来计算两条路径的相似性。该算法最初用于生物信息学中 DNA 和蛋白质的局部序列对齐,其基本思想是:
- 若两段序列的某一部分在顺序上具有相似模式,则该部分将获得高对齐得分;
- 算法可处理变长序列,并具有容错能力(可接受插入/删除/不匹配);
- 我们使用特征向量之间的余弦相似度或L1距离作为序列间单元素的匹配得分 \(s(a_i, b_j)\),并设定合适的惩罚值 \(d\) 控制不匹配惩罚。
具体的动态规划公式为:
\[ M_{i,j} = \max \begin{cases} 0, \\ M_{i-1,j-1} + s(a_i, b_j), \\ M_{i-1,j} + d, \\ M_{i,j-1} + d \end{cases} \]
其中:
- \(M_{i,j}\) 表示第一个序列第 \(i\) 个元素与第二个序列第 \(j\) 个元素匹配的最大得分;
- \(s(a_i, b_j)\) 是两个注视点特征的匹配得分;
- \(d\) 是插入或删除的惩罚(通常为负值);
- 最终相似度由矩阵中最大值决定,表示两条扫视路径的局部最相似子序列的得分。
相似度评估结果
为了度量不同被试者之间在整个图像集合中的注视行为相似性,我们采用 Smith-Waterman 局部序列比对算法对两位被试者在每张图像上的扫视路径进行比对,并计算所有图像类别下相似度的平均值,得到整体相似度指标。结果储存在similarity_averages_VGG16.csv中。
如下表所示,Key 表示两个被试者的姓名简写,例如 ac-hn 表示被试者 ac 和 hn 的扫视路径平均相似度为 61.68,表示在整个图像集下他们观察行为的整体相似性。
| 被试对(Key) | 平均相似度(Average) |
|---|---|
| ac-hn | 61.68 |
| fh-hn | 61.43 |
| fh-ac | 73.69 |
| fl-ac | 64.94 |
| fl-fh | 71.92 |
| … | … |
| fc-ms | 81.85 |
| fc-av | 83.86 |
| fc-pc | 71.87 |
| fc-td | 77.40 |
| rt-hn | 63.47 |
可以看出,部分个体之间的平均相似度较高(如 fc-av 达到 83.86),说明其在面对相同类别图片时呈现出高度一致的注视路径,可能是由于被图像显著区域共同吸引或具备类似的视觉策略。而某些被试对之间的相似度较低,表明他们对同一图像采取了更为个性化的观察方式。
方法二:基于 I3D 的注视点序列特征提取
传统的扫视路径分析方法(如使用 VGG16 + Smith-Waterman)忽略了注视点之间的时序连贯性。实际上,人在观看图像时,注视点序列蕴含了强烈的时间结构:人眼的移动是有目的、受上下文影响的。若将观察序列看作时间维度上的图像切片,就类似一个“局部动态视频”。因此我们尝试采用视频特征提取网络 I3D(Inflated 3D ConvNet)对这种“注视视频”进行建模。
图像转视频:GIF 构造
为了将注视序列转化为适用于 I3D 的输入,我们将每个被试者对单张图片的注视点序列转换为一个 GIF 动图,每一帧表示一个注视点的图像区域(Patch)。这可以模拟出人眼随着时间在图像上移动并逐步聚焦不同区域的过程。
以下是 GIF 生成的过程要点:
- 对每张图像,读取被试者的注视点数据(X, Y 坐标)。
- 以每个注视点为中心裁剪 100×100 像素的图像区域。
- 将这些区域依序拼接为帧,保存为 GIF 动图,帧率可调整(如 250ms/帧)。
# 伪代码示意,已省略细节
for i in range(len(fixations)):
x, y = fixations[i]
patch = crop(image, center=(x, y), size=(100, 100))
frames.append(patch)
save_gif(frames, path)这样,我们就为每位被试者每张图生成了一个观察过程的动态视频,用于后续的特征提取。下图展示了一位被试者(2-54-hn)观看图像 001.jpg(类别:Action)时的注视序列,注视点按照时间顺序依次裁剪并拼接为 GIF 动图,模拟观察过程:

图:注视点序列转化为 GIF 示例。每一帧表示一个注视点对应的图像区域,反映观察路径的时序动态。
I3D 模型提取注视路径特征
为更好地模拟观察者的视觉时序过程,我们将注视点裁剪图像按时间顺序合成为 GIF 动图,并使用 I3D 模型提取视频级特征。主要步骤如下:
读取 GIF:加载某个被试的注视路径 GIF,逐帧读取并转为 RGB 图像。
帧数补齐:若帧数少于
min_frames(如16),则循环补齐;超过max_frames则裁剪。图像预处理:每帧图像缩放至
224x224,转为张量格式并堆叠为[1, 3, T, H, W]的输入。加载 I3D 模型:
- 使用 ImageNet 上预训练的
Inception I3D(输入通道为 3)模型; - 加载模型权重(
.pt文件)并迁移到可用设备。
- 使用 ImageNet 上预训练的
提取特征:
- 调用
extract_features方法提取时序特征; - 使用
mean操作对空间和时间维度进行全局池化,得到[1, 1024]的向量表示。
- 调用
输出结果:最终返回一个 1024 维的视觉-时间嵌入向量,表示该被试对该图片的观看行为特征。
扫视路径相似性计算(Scanpath Similarity)
由于使用 I3D 模型提取的特征是一个统一的嵌入向量(而非序列嵌入数组),因此我们可直接使用 余弦相似度(cosine similarity) 来衡量两条扫视路径之间的相似性。具体来说,假设两个被试在同一图像上的观看行为分别被表示为特征向量 \(\mathbf{f}_1\) 和 \(\mathbf{f}_2\),其相似度计算公式如下:
\[ \text{Similarity} = \frac{\mathbf{f}_1 \cdot \mathbf{f}_2}{\|\mathbf{f}_1\| \|\mathbf{f}_2\|} \]
相似度越高,表示两个观察者在观看同一图像时的视觉注意行为越相似。
相似度评估结果
通过 I3D 提取扫视路径特征后,我们使用余弦相似度对所有参与者在各类别图像上的注视行为进行两两比较,得到相似度得分。下表展示了部分参与者对之间的平均相似度结果(Key 表示两位被试者的姓名缩写,Average 为其在所有图像类别下的平均余弦相似度):
Key Average
0 ac-hn 0.8494
1 fh-hn 0.8317
2 fh-ac 0.8529
3 fl-ac 0.8295
4 fl-fh 0.8396
⋮ ⋮ ⋮
1936 jg-am 0.8639
1937 jg-aa 0.8487
1938 jg-hc 0.8331
1939 jg-jh 0.8449
1940 jg-js 0.8305可以看出,大多数被试对之间的相似度均高于 0.83,表明在相同任务下,不同个体的视觉注意模式存在一定程度的一致性。结果储存在similarity_averages_GIF.csv中。
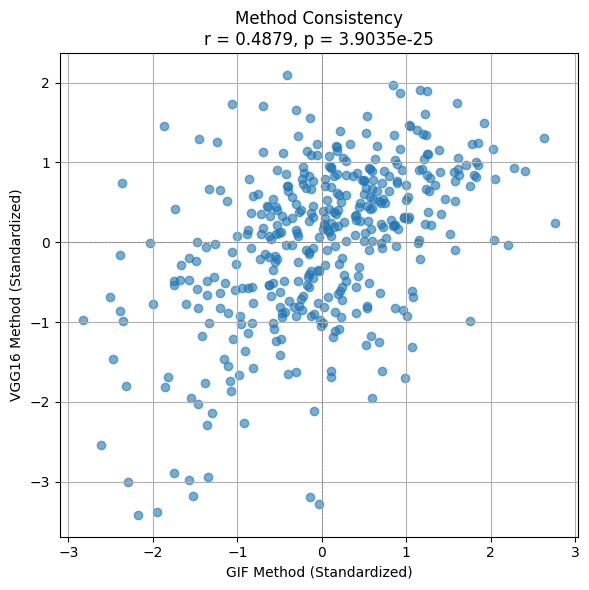
方法一致性检验
由于两种方法(VGG16图像块特征 vs I3D-GIF特征)输出的相似度值数值范围差异较大,我们对结果进行了标准化处理,然后使用皮尔逊相关系数来评估两者的一致性:
- Pearson r = 0.4879
- p-value = 3.9035 × 10⁻²⁵
结果显示两者具有显著正相关性,说明这两种方法在评估扫视路径相似性方面具有较强一致性,可相互验证其有效性。
并插入下图以直观展示两方法的一致性关系: