注视模式的个性化预测(三)
数据集
我们选择了开源数据集CAT2000,虽然从发文章的角度来看我更喜欢实验室提供的“自制”数据集,因为这样数据集本身也是贡献的一部分,能够收集到第一手数据是实验室实力的体现。好的实验室或者课题组应该是站在实践的第一线的,这样任何发现都是创新。不过既然没有“自制”数据集,那么就用开源数据集吧。我认为维护开源数据集本身对科学也是很大的贡献,这些统一的数据集让各种方法可以相互比较,开源数据集就是学术上的基础设施。在计算机领域,我们都乐意把自己制作的数据集拿出来分享,甚至其他人也认可维护数据集是你的重要贡献。但其他学科并不是这样,比如化学你的实验数据本身就是你的研究成果,所以数据库一般是由大的研究院维护比如PubChem由美国国立卫生研究院(NIH)维护,ChEMBL由欧洲生物信息学研究所(EMBL-EBI)提供。很少看到有人在网络上分享自己的数据,但这还算好的。一些历史类研究就更离谱,把一些文献资料利用自己的特殊身份隐藏起来,供自己和门下学生持久产出该领域内容,完成垄断。甚至还有一些历史类文物是通过侵略得到的,到了文明世界都不愿共享研究资料。
这个数据集有个问题,它的图片文件用JPG格式分类放在各个文件夹下,但是眼动数据却都是放在一个.mat文件1中的,这甚至不是常见数据格式(CSV、JSON、XML),最重要的是python用于读取.mat的包scipy.io无法读取复杂的.mat文件而恰好存储所有眼动数据的文件就属于复杂的.mat文件,因为它有Matlab的独特数据结构。那我就没办法了必须用Matlab进行转换,虽然Matlab有试用期足够转换一下,但是我还是去淘宝买了个永久授权的,只要180人民币。然后我把每个个体的眼动数据转换成.csv文件放到图片同名文件夹下。每张图片大概有18个数据。转化完我就知道,人家为什么不这样做了。如图@fig-fixations
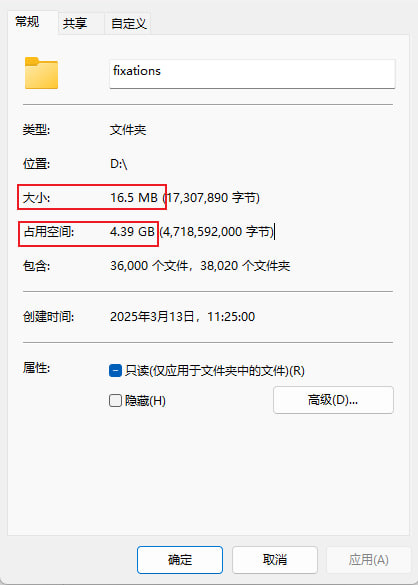
这样做虽然访问数据直观,并且在测试时可以访问指定的数据,但是小文件会产生大量内存碎片占用空间,以及批量访问耗时。虽然我们后续整理内存碎片可以把占用空间缩小到16MB,但如此多的文件我相信对于git也是负担。
相关论文中也有关于数据收集的详细信息,比如可视角度,每一角度对应的像素多少,等等重要信息,我们之后会用到。
特征提取方式
我们采用VGG16来进行特征提取,VGG16是一个深度卷积神经网络,由牛津大学的视觉几何组(Visual Geometry Group)开发。它在 ImageNet 数据集上表现出色,并且在许多计算机视觉任务中被广泛使用。大致可以理解成先卷积再通过全连接层分类,所谓特征就在卷积之后,全连接层是通过特征进行分类的,把物体的特征对应成分类的名词。
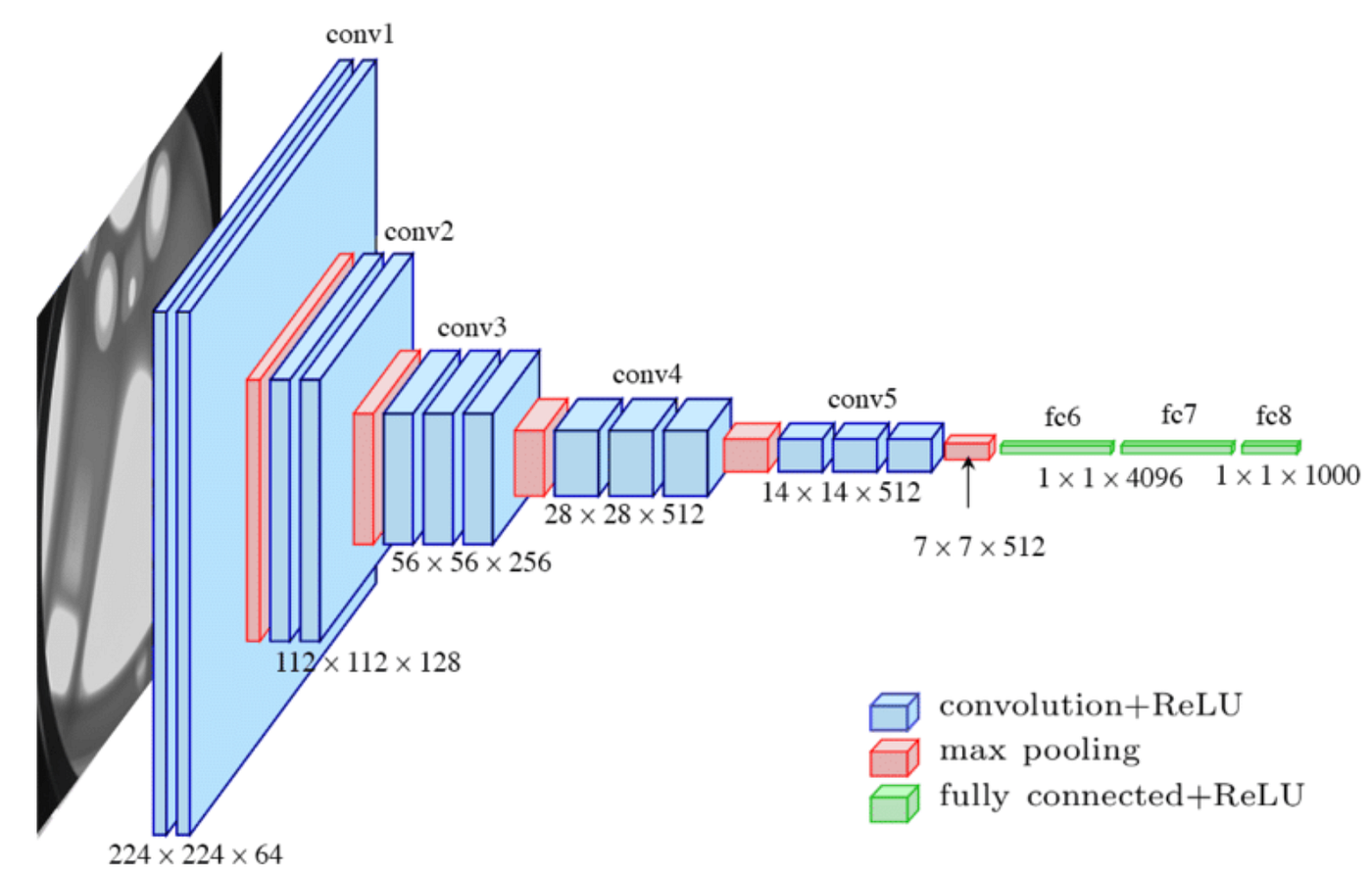
正如我在之前文章中说过的特征就是“机器世界”对于物体的描述,表现为一连串的浮点数,这串浮点数标记这该物体像什么,就像人类明确看见了一个物体但想不到对应的名词去描述一样。后续全连接层则是通过监督学习完成“像什么”到“是什么”的对应,在这里,你即使不知道一个东西怎么说,你仍然可以通过它“像什么”的描述知道两个事物是否相似,我们就由描述相似性推测现实相似性。既然描述是一串数字那么我们就可以用判断一串数字的相似性的方法去判断,可以用余弦相似度或者相关性系数,也有用绝对值相差之和的。
提取区域的大小
VGG16 网络设计用于处理 224×224 像素的输入图像,但我们都知道图片是可以放大缩小的,所以只要经过调整,VGG16 可以处理任意大小的输入图像。但是我们应该选取多大区域的图块来进行特征提取呢。我认为人能够关注的范围应该有生物学基础,就比如下图
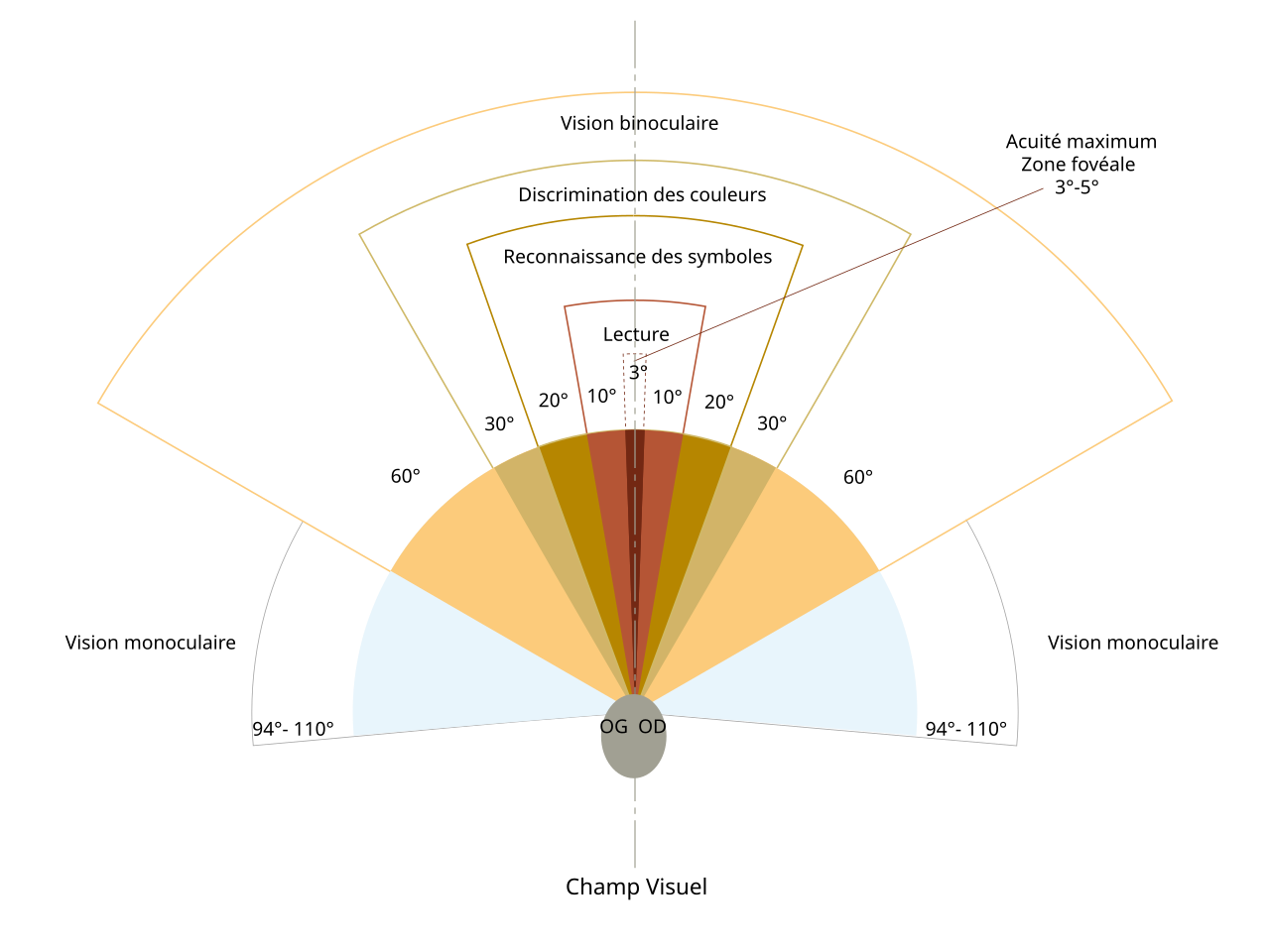
实际上人眼不同于照相机,相机是在CMOS上成像,CMOS是感光元件。但是人眼的感光细胞并不像CMOS那样均匀分布,感光细胞在“中央凹”最密集,这也是我们所谓“清楚观测”的范围就是3到5度,只不过眼球是可以转动的,当我们要看下一个区域的时候我们就把“中央凹”转过去,通过这小范围的清晰图像,我们脑补出全视野的清晰图像。不如就把人脑的辨认范围用作图片的特征提取范围。那我们要进行一些计算, 我们知道每度是38像素,那么3度到5度就是,114像素到190像素,由于中国人喜欢折衷,我就选择4度152像素。
degree of visual angle or dva about 38 pixels(see Borji and Itti 2015)
提取区域的形状
由于人眼的中央凹大致是圆形或椭圆形,而不是方形,所有我用等面积的圆形替换掉152x152像素的方形来进行测试看是否能够提升效果。用圆形的提取区域是最自然的,但是VGG16网络特征提取只支持正方形,所有要经过填充,计算机术语叫“掩码”。然后才能够进行特征提取。具体效果,我需要对比才可以知道,但是这是合理的。不过考虑到正方形和等面积的圆实际上相差不大,所有也不会有突飞猛进的效果。
用Telegram机器人监督程序运行进度
由于提取特征相对来说是一个耗时工作,以下输出是处理一张图片的典型时间。我们可以看见,在输出形状和内容一致的情况下,英伟达的CUDA可以快超过一倍,但是你要注意这个CUDA优化不是自动的,你仍然需要将数据和模型在源代码中手动加载到GPU中,不过几行代码就可以搞定,还算简单。
Execution time with CUDA: 1.7064645290374756 seconds
Execution time without CUDA: 3.847055196762085 seconds
Shapes are equal: True
Contents are equal: True但是我有十几个类别,每个类别有1000张图片,即使用CUDA也是不少的时间。如下图所示,整整用了一个晚上的时间。
============For loop started at: 2025-04-15 14:20:10 (French time)============
Code execution time for category Action : 3256.5604066848755 seconds
Code execution time for category Affective : 3176.295798301697 seconds
Code execution time for category Art : 3157.118818283081 seconds
Code execution time for category BlackWhite : 3187.5288138389587 seconds
Code execution time for category Cartoon : 3221.3386948108673 seconds
Code execution time for category Fractal : 3053.383510351181 seconds
Code execution time for category Indoor : 3121.4215433597565 seconds
Code execution time for category Inverted : 3287.2581498622894 seconds
Code execution time for category Jumbled : 3141.990884780884 seconds
Code execution time for category LineDrawing : 3040.485256910324 seconds
Code execution time for category LowResolution : 2959.2536947727203 seconds
Code execution time for category Noisy : 3027.11469745636 seconds
Code execution time for category Object : 3060.5700261592865 seconds
Code execution time for category OutdoorManMade : 3177.311723947525 seconds
Code execution time for category OutdoorNatural : 3070.029595851898 seconds
Code execution time for category Pattern : 2999.9442071914673 seconds
Code execution time for category Random : 3216.371661424637 seconds
Code execution time for category Satelite : 3174.0594351291656 seconds
Code execution time for category Sketch : 3078.3522112369537 seconds
Code execution time for category Social : 3295.646829366684 seconds
============For loop completed at: 2025-04-16 07:45:12 (French time)============我不是优化高手,没法让这个时间缩短。但我决定让这个过程变得有趣。我已经给它们的运行过程加上进度条了。现在我决定将程序执行进度通过Telegram机器人推送到手机上,这样我就可以随时知道程序运行的进度,等待过程就不那么无聊,同时还能返回最新的运行结果,方便出现不测随时干预。与此同时为了防止运行中断丢失进度,记得随时保存运行的结果,并且给程序加上读取之前结果并且继续运行的功能。这样可以增强系统的稳定性,保证出现问题重启就好了。当然这只是我的开发习惯。Telegram机器人的代码可以参见我的GitHub仓库,如果需要的话你可以标记一下,或者针对你的代码情况进行二次开发。
References
Footnotes
是MATLAB专有的二进制文件格式,用于存储变量和数据。这种格式在MATLAB环境中非常常用,因为它能够高效地保存和加载复杂的数据结构。↩︎